python爬取当当网的书籍信息并保存到csv文件
- 依赖的库:
- requests #用来获取页面内容
- BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装BeautifulSoup4(pip install bs4)
此实验爬取了当当网中关于深度学习的书籍,内容包括书籍名称、作者、出版社、当前价钱。为方便,此实验只爬取搜索出来的一个页面的书籍。具体步骤如下:
- 1 打开当当网,搜索“深度学习”,等待页面加载,获取当前网址
“http://search.dangdang.com/?key=%C9%EE%B6%C8%D1%A7%CF%B0&act=input" - 2 点击鼠标右键,选择’检查’,获取当前页面的网页信息
- 3 分析网页代码,截取我们要的内容。
- 4 实验设计为:先从搜索’深度学习‘后得到的页面中抓取相关书籍的链接(url);然后再遍历每个url,从该书籍的具体页面中寻找信息。(如果单单是爬取我上面的那些内容的话,好像不用进去每个书籍的链接 直接在搜索出来的页面获取 也可以。。。)
下面是具体代码
1 | import requests |
http://product.dangdang.com/25111382.html
http://product.dangdang.com/25089622.html
http://product.dangdang.com/25231551.html
http://product.dangdang.com/25234782.html
http://product.dangdang.com/25224111.html
http://product.dangdang.com/23993317.html
http://product.dangdang.com/25073661.html
http://product.dangdang.com/25245282.html
http://product.dangdang.com/25208778.html
http://product.dangdang.com/25212175.html
http://product.dangdang.com/25175809.html
http://product.dangdang.com/23983230.html
http://product.dangdang.com/24104547.html
http://product.dangdang.com/25124666.html
http://product.dangdang.com/23996903.html
http://product.dangdang.com/25082459.html
http://product.dangdang.com/25207334.html
http://product.dangdang.com/25104088.html
http://product.dangdang.com/25163815.html
http://product.dangdang.com/25118239.html
http://product.dangdang.com/25105666.html
http://product.dangdang.com/25208772.html
http://product.dangdang.com/24049457.html
http://product.dangdang.com/25234806.html
http://product.dangdang.com/25230551.html
http://product.dangdang.com/25166563.html
http://product.dangdang.com/24165179.html
http://product.dangdang.com/25250547.html
http://product.dangdang.com/25262534.html
http://product.dangdang.com/25098329.html
http://product.dangdang.com/25225304.html
http://product.dangdang.com/23925889.html
http://product.dangdang.com/25261023.html
http://product.dangdang.com/25269988.html
http://product.dangdang.com/25138676.html
http://product.dangdang.com/25125879.html
http://product.dangdang.com/25250993.html
http://product.dangdang.com/25243399.html
http://product.dangdang.com/1057511057.html
http://product.dangdang.com/25066760.html
http://product.dangdang.com/24195829.html
http://product.dangdang.com/25119333.html
http://product.dangdang.com/24048571.html
http://product.dangdang.com/25269074.html
http://product.dangdang.com/25182369.html
http://product.dangdang.com/25189701.html
http://product.dangdang.com/25251315.html
http://product.dangdang.com/25255372.html
http://product.dangdang.com/1230199397.html
http://product.dangdang.com/25073507.html
http://product.dangdang.com/1336821476.html
http://product.dangdang.com/25190949.html
http://product.dangdang.com/1365765197.html
http://product.dangdang.com/25215200.html
http://product.dangdang.com/25242647.html
http://product.dangdang.com/1211962291.html
http://product.dangdang.com/25261676.html
上面就是获取到的每本书的url,下面来处理每本书的url,获取每本书的信息:
1 | def get_book_information(book_url): |
1 | import csv |
1 | if __name__ == '__main__': |
获取了0条信息,一共57条信息
获取了10条信息,一共57条信息
获取了20条信息,一共57条信息
获取了30条信息,一共57条信息
获取了40条信息,一共57条信息
获取了50条信息,一共57条信息
至此,爬虫结束,查看当前目录,就可以找到我们刚刚保存的DeepLearn_book_info.csv文件啦,打开查看,便得到下面的内容:
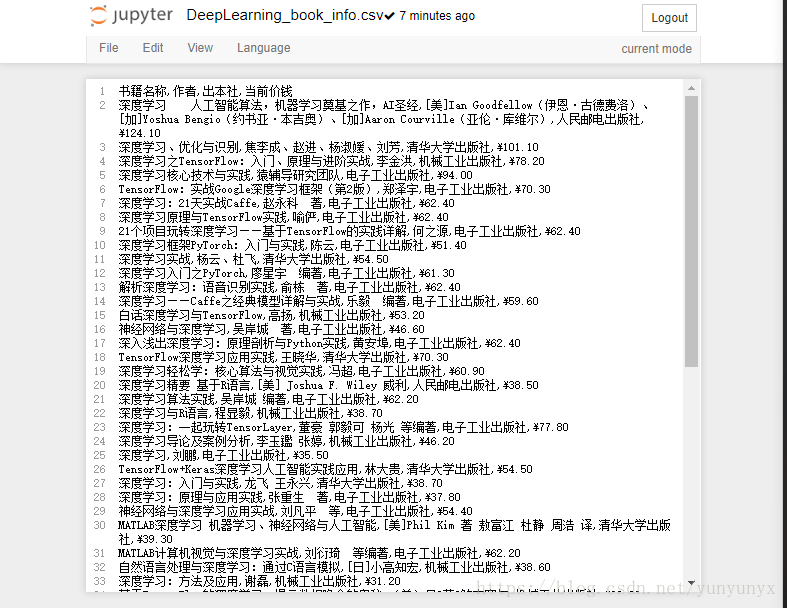
这样就把我们想要的书籍信息保存到csv文件啦。

